


What is feature selection?
Feature Selection is the method of selecting features from the existing set to be used for modeling. It doesn't create new features.
Goal: Improve model's performance
One of the easiest ways is to determine where a feature is redundant or not.
Redundant Features
- Remove noisy features
- Remove correlated features
- Remove duplicated features
Feature selection is an iterative process.
Correlated Features
Linear models in general assume feature independence. In cases where features are statistically correlated, moving together directionally; can introduce bias. Pearson Correlation Coefficient is the measure for this. A score closer to :
1indicates a strong positive correlation0indicates no correlation-1indicates a strong negative correlation. It implies that the features move in the opposite direction
Selecting features using Text Vectors
After you have vectorized the text, vocabulary and weights will be stored in the vectorizer. To pull out the vocabulary list, in order to have a look at word weights, you can use the vocabulary attribute.
Here, we have a vector of location descriptions from the hiking dataset,
print(tfidf_vec.vocabulary_)

Row data contains two components:
- word weights
- index of word
To take a look at weights in the fourth row, we use the data attribute on a specific row, like you would access items in a list.
print(text_tfidf[3].data)
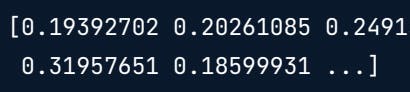
To get the indices of the words that have been weighted, we use the indices attribute.
print(text_tfidf[3].indices)

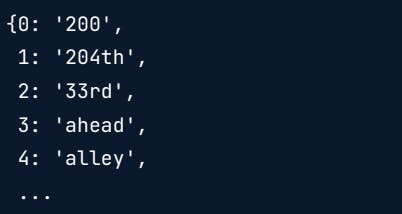
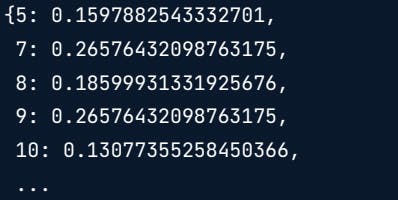
It will be easier later on if we have the index number in the key position in the dictionary. To reverse the vocabulary dictionary, you can swap the key-value pairs by grabbing the items from the vocabulary dictionary and reversing the order. Finally, we can zip together the row indices and weights, pass them into the dict function and turn it into a dictionary.
vocab = {v:k for k,v in tfidf_vec.vocabulary_.items()}
zipped_row = dict(zip(text_tfidf[3].indices,text_tfidf[3].data))
print(vocab)
print(zipped_row)
def return_weights(vocab,vector,vector_index):
zipped = dict(zip(vector[vector_index].indices,vector[vector_index].data))
return {vocab[I]:zipped[I] for I in vector[vector_index].indices}
print(return_weights(vocab,text_tfidf,3))

Check out the exercises linked to this here
Interested in Machine Learning content? Follow me on Twitter and HashNode.