


What is Feature Engineering?
Feature Engineering is the process of the creation of new features based on existing features.
It can add features important for clustering tasks or insight into relationships between features.
Real-world data is not in its entirety and you lively have to expand and extract data in addition to preprocessing steps like standardization.
Encoding categorical variables
Since the models in scikit-learn require numerical inputs, you will need to encode categorical data.
Using Pandas
Using apply we can replace the values.
users["sub_enc"] = users["subscribed"].apply(lambda val:
1 if val=="y" else 0)
Using scikit-learn
Alternatively, we can also do this using scikit-learn's Label Encoder method. This is helpful if it is being implemented using the scikit-learn's pipeline functionality.
Creating a LabelEncoder object helps us reuse it for training test-set or new data as well.
You can use the fit_transform method to both fit the encoder to data and transform the column.
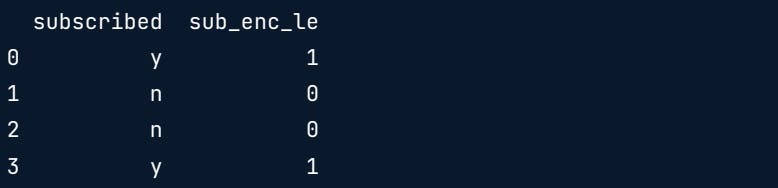
Printing out the columns we can see how the y's and n's have been encoded to 1's and 0's.
from sklearn.preprocessing import LabelEncoder
le =LabelEncoder()
users["sub_enc_le"] = le.fit_transform(user["subscribed"])
print(users[["subscribed","sub_enc_le"]])
One-Hot Encoder
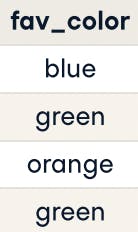
When we have more than 1 value to encode we can use One-Hot Encoding. For example, the fav_color column has 3 different colors: blue, green, and orange
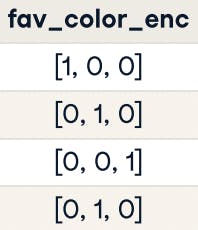
It will be encoded as follows:
- blue:[1,0,0]
- green: [0,1,0]
- orange[0,0,1]
This operation can be done using the get_dummies method on the desired column.
print(pd.get_dummies(users["fav_color"]))

Engineering Numerical Features
This can be helpful in dimensionality reduction.
Say you have a table of temperature readings over 3 days from 4 different cities. Given that the temperature readings are close enough to their values, it would be more appropriate to take the average value.
Here, we are applying lambda to get the mean of values. Axis=1 is specified to operate across the row.
columns = ["day1", "day2" , "day3"]
df["mean"] = df.apply(lambda row: row[columns].mean(), axis=1)
print(df)

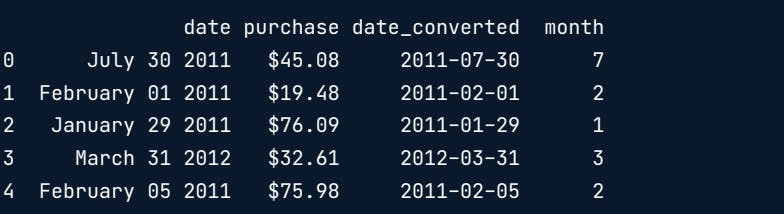
In the case of dates, it is much more useful to reduce the granularity.
df["date_converted"] = pd.to_datetime(df["date"])
df["month"] = df["date_converted"].apply(lambda row:row.month)
print(df)
Text Classification
Let's extract numbers from a string.
import re
my_string = "temperature is 75.6 F"
pattern = re.compile("\d+\.\d+")
temp = re.match(pattern,my_string)
print(float(temp.group(0)))
Here:
\dis used to extract digits+sign helps in extracting as many digits as possible\.considers the decimal point
Vectorizing Text
We will be using tf/idf.
tf/idf is a way of vectorizing text that reflects how important a word is in a document beyond how frequently it occurs.
It stands for
- tf: term frequency
- idf :inverse document frequency
It places the weight on words that are ultimately more significant in the entire corpus of words.
from sklearn.feature_extraction.text import Tfidfvectorizer
print(documents.head())
tfidf_vec = TfidfVectorizer()
text_tfidf = tfidf_vec.fit_transform(documents)
We will be using Naive Bayes Classifier for text classification. It treats each feature as independent from others, which can be a naive assumption but works well on text data.
Check out the exercises linked to this here
Interested in Machine Learning content? Follow me on Twitter and HashNode.