


What is Data Preprocessing?
Data Preprocessing comes right in after you have cleaned up your data and done some Exploratory Data Analysis. It is the step where we prepare the data for modeling. Modeling in Python needs numerical input.
Refreshing Pandas Skills
You can skip this section if you know the basics.
Before we proceed with the series, it is important to know the commands that can assist you in knowing your dataset well.
import pandas as pd
hiking = pd.read_json("datasets/hiking.json")
print(hiking.head())

print(hiking.columns)
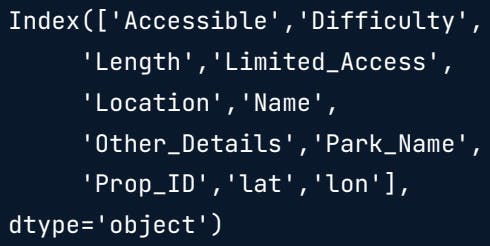
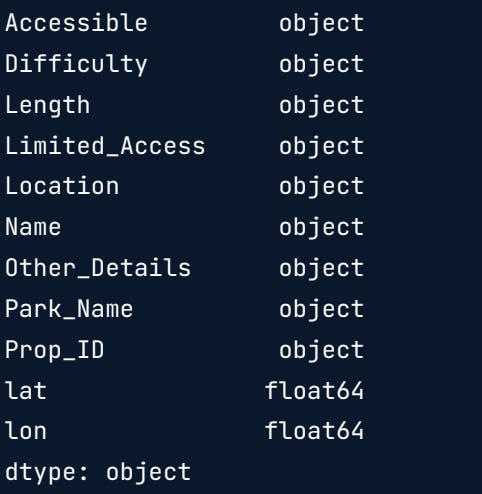
print(hiking.dtypes)
Removing Missing Data
Sample Data
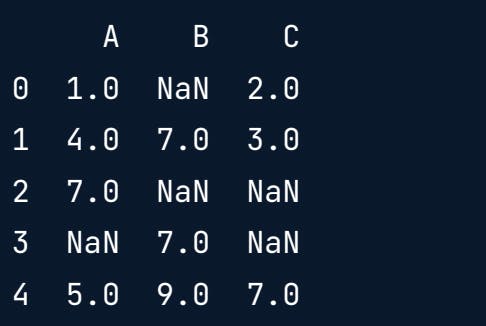
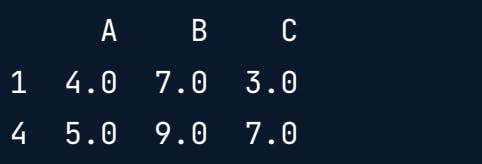
Dropping rows with null values
print(df.dropna())
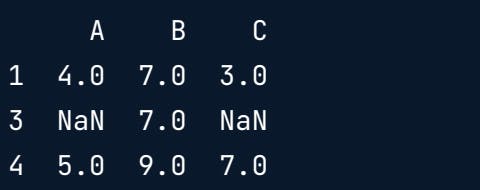
Dropping specific rows from using an array
print(df.drop([1,2,3]))
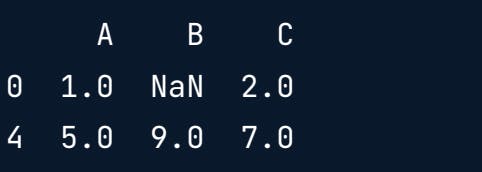
Dropping a specific column(here axis=1 specifies that column needs to be dropped.)
print(df.drop("A", axis=1))
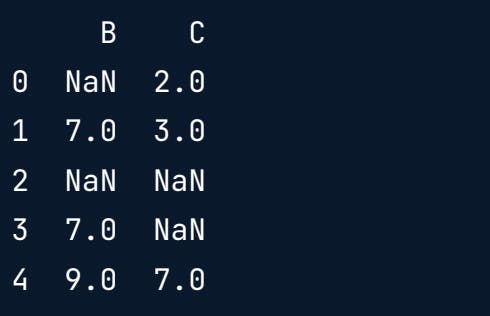
Fetching the not null rows from a specific column.
print(df[df["B"].notnull()])
Working on DataTypes
While preprocessing the data, many times the datatype of columns is not as desired. We use the following command to convert the column datatype.
Remember: Always apply the datatype that fits all of the data in the particular column.
This code sample will help you convert column "C" to the float datatype.
df["C"] = df["C"].astype("float")
print(df.dtypes)
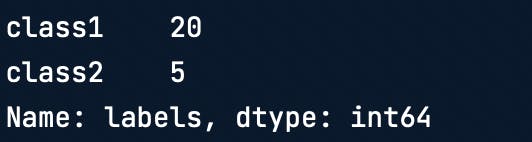
Stratified Sampling
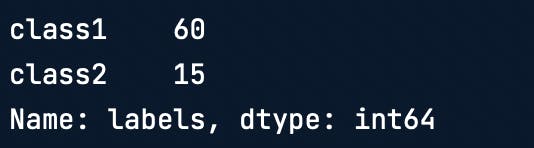
Train test split is done on the dataset for training and testing the model. Say, the original dataset is 80% class 1 and 20% class 2. You would want a similar distribution in both train and test datasets to make sure you have the best representation.
# Total "labels" counts
y["labels"].value_counts()

X_train,X_test,y_train,y_test = train_test_split(X,y, stratify=y)
y_train["labels"].value_counts()
y_test["labels"].value_counts()
Check out the exercises linked to this here
Interested in Machine Learning content? Follow me on Twitter and HashNode.